0. 이론은 알고 있었는데
인덱스에 대한 이론은 대학에서부터 배웠다.
- 책갈피를 만드는 것과 같다.
- 조회 성능이 빨라진다.
EXPLAIN으로 쿼리 실행 계획을 확인하고 튜닝하면 된다.- 어쩌고 저쩌고~~
아 그래 좋은거구나~ 데이터베이스 강의들의 성적은 항상 A+이었는데 정작 인덱스가 정확히 어떤 타이밍에 필요한지,
튜닝을 어떻게 해야 하는지 전혀 들어보지 못했다.
조회 성능이 상승된다고는 하지만 조회 성능을 끌어내야 할 만큼의 상황도 지금까지 겪지 못했던 것 같다.
사이드 프로젝트는 데이터가 많지도 않았고, 회사에서 맡고 있는 제품은 B2B라서 비교적 데이터가 많지 않으면서 건드리기 무서웠다.
(글을 쓰는 지금 생각해보면 회사에서는 인덱스니 캐시를 빡빡하게 넣어줘서 개선할 여지가 많다.)
더 이상 데이터가 적어서 인덱스 크게 생각 안 해봤는데.. 라는 말로 미룰 수 없는 타이밍이 왔다.
직접 많은 데이터를 생성해보고 부하 테스트를 해보며 인덱스가 왜 필요한지 겪어봐야 할 때다.
데이터는 의미 없는 이름을 넣기보다 실제와 유사한 값을 만들고 싶어 파이썬으로 작성했다.
10만 건의 상품 데이터 CSV를 만들었고 DataGrip으로 테이블에 데이터를 넣었다.
테스트에는 k6를 사용했다. 나도 처음 써봤으니 가이드는 생략한다. 나중에 또 필요한 시점이 있다면 그때 작성해보는걸로..
그리고 패기롭게 시작한 테스트.
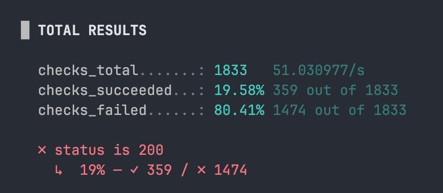
내 맥북을 너무 믿었나? 얌전히 실행 횟수를 좀 내려야겠다.
1. 인덱스 없이 테스트 해보기
동시 접속자 수는 100명으로, 1.5초 간격으로 30초 동안 요청한다.
(1초면 실패가 생겼다.)
1) 100개의 상품을 등록 일자 내림차순으로 조회
| 지표 | 값 |
|---|---|
| 평균 | 4.61s |
| 최소 | 494.01ms |
| 중앙값 | 4.83s |
| 최대 | 7.08s |
| p(90) | 6.64s |
| p(95) | 6.83s |
| 실패율 | 0% (0/524) |
| 요청 수 | 524 (15.64/s) |
2) 100개의 상품을 가격 오름차순으로 조회
| 지표 | 값 |
|---|---|
| 평균 | 4.97s |
| 최소 | 204.45ms |
| 중앙값 | 5.49s |
| 최대 | 7.85s |
| p(90) | 6.72s |
| p(95) | 6.98s |
| 실패율 | 0% (0/501) |
| 요청 수 | 501 (14.80/s) |
3) 100개의 상품을 좋아요 내림차순으로 조회
| 지표 | 값 |
|---|---|
| 평균 | 4.79s |
| 최소 | 581.15ms |
| 중앙값 | 4.97s |
| 최대 | 7.53s |
| p(90) | 6.85s |
| p(95) | 7.02s |
| 실패율 | 0% (0/515) |
| 요청 수 | 515 (15.28/s) |
4) 100개의 상품을 좋아요 내림차순으로 조회 + 브랜드 필터
| 지표 | 값 |
|---|---|
| 평균 | 185.86ms |
| 최소 | 52.16ms |
| 중앙값 | 93.76ms |
| 최대 | 1.32s |
| p(90) | 402.05ms |
| p(95) | 995.16ms |
| 실패율 | 0% (0/1824) |
| 요청 수 | 1824 (57.98/s) |
2. 빨라야 하는 조회는 무엇일까?
이커머스는 본질적으로 읽기 위주 서비스다. “다 빠르면 좋지!” — 맞는 말이지만, 무턱대고 모든 조회를 빠르게 만드는 건 효율적이지 않다.
인덱스는 디스크 공간을 사용하고, 캐시는 RAM을 차지한다. 여기에 인덱스와 캐시를 무분별하게 적용하면 쓰기 지연, 락 경합, 캐시 동기화 문제까지 발생할 수 있다. 가장 단순하고도 큰 문제는 비용이다. 우리는 비즈니스 관점에서도 생각해야 하므로, 최대한 적은 비용으로 가장 큰 효율을 내야 한다.
따라서 우선순위를 정하는 것이 중요하다. 핵심은 “많이 사용되고, 느리면 사용자가 체감하는 조회”를 먼저 빠르게 만드는 것이다.
예를 들어, 목록 조회는 항상 정렬 조건이 들어가고, 특히 1~5페이지 구간이 가장 많이 접근된다. 또한 카테고리 필터나 브랜드 필터처럼 사용 빈도가 높은 조건도 자주 쓰인다.
결국 빨라야 하는 조회 = 사람들이 자주 쓰는 조회 = 이커머스에서 기본으로 제공하는 주요 정렬 순서다. 즉, ORDER BY 절에 들어가는 컬럼들은 인덱스 적용이 거의 필수다.
3. 쿼리의 함정
문제는 분명 인덱스를 걸었는데도 속도가 전혀 개선되지 않은 경우가 있었다는 점이다.
쿼리를 확인해보니, ORDER BY 절 안에 CASE WHEN 구문을 넣고 있었는데,
GPT에게 물어보니 이 경우 인덱스를 전혀 탈 수 없다고 한다.
실제 회사 서비스에서도 이런
CASE WHEN기반 정렬이 빈번하게 쓰이고 있었다.
“혹시 이게 느린 원인 아닌가?” 하고 캐치한 것도 이번 실험 덕이었다.
사내에서 개선을 적용하고 실력을 뽐내봐야겠다.
즉, ORM을 쓴다고 무조건 인덱스 최적화 효과를 볼 수 있는 게 아니며, 실행 계획을 반드시 확인해야 한다.
4. 인덱스와 함께 테스트 해보기
동일 조건(동시 접속자 100명, 1.5초 간격, 30초)에서 테스트.
1) 100개의 상품을 등록 일자 내림차순으로 조회
| 지표 | 값 |
|---|---|
| 평균 | 39.48ms |
| 최소 | 12.62ms |
| 중앙값 | 25.01ms |
| 최대 | 285.37ms |
| p(90) | 65.75ms |
| p(95) | 131.47ms |
| 실패율 | 0% (0/2000) |
| 요청 수 | 2000 (64.47/s) |
2) 100개의 상품을 가격 오름차순으로 조회
| 지표 | 값 |
|---|---|
| 평균 | 49.18ms |
| 최소 | 12.64ms |
| 중앙값 | 30.24ms |
| 최대 | 241.28ms |
| p(90) | 123.84ms |
| p(95) | 168.14ms |
| 실패율 | 0% (0/2000) |
| 요청 수 | 2000 (64.20/s) |
3) 100개의 상품을 좋아요 내림차순으로 조회
| 지표 | 값 |
|---|---|
| 평균 | 47.29ms |
| 최소 | 12.95ms |
| 중앙값 | 31.78ms |
| 최대 | 351.44ms |
| p(90) | 80.53ms |
| p(95) | 135.61ms |
| 실패율 | 0% (0/2000) |
| 요청 수 | 2000 (64.40/s) |
4) 100개의 상품을 좋아요 내림차순으로 조회 + 브랜드 필터
| 지표 | 값 |
|---|---|
| 평균 | 36.76ms |
| 최소 | 3.87ms |
| 중앙값 | 23.57ms |
| 최대 | 303.97ms |
| p(90) | 42.81ms |
| p(95) | 80.10ms |
| 실패율 | 0% (0/2000) |
| 요청 수 | 2000 (65.00/s) |
5) 100개의 상품을 좋아요 내림차순으로 조회 + 조건 변경(동시 접속자 300명, 0.3초 간격, 30초) 테스트
| 지표 | 값 |
|---|---|
| 평균 | 362.36ms |
| 최소 | 31.29ms |
| 중앙값 | 332.26ms |
| 최대 | 1.91s |
| p(90) | 562.38ms |
| p(95) | 678ms |
| 실패율 | 0% (0/13707) |
| 요청 수 | 13707 (449.14/s) |
5. 마무리
비교도 안 되게 빨라졌다. 이 정도면 캐시까지도 필요 없을 정도다. 부하 테스트에서 실패했던 조건보다 더 빡세게 걸어도 성공을 해버린다.
다만, SQL을 반드시 확인해야 한다. (EXPLAIN도 함께!)CASE WHEN 같은 구문이 ORDER BY에 들어가면 인덱스는 무용지물이 된다.
이번 테스트로 그런 숨은 병목까지 발견할 수 있었다.
결과만 만들어지면 장땡인 쿼리를 지금까지 얼마나 대충 만들고 대충 써왔는지 반성…
회사의 문제 있는 쿼리들을 개선을 해봐야겠다.
thanks to loopers..